
KubeCon+CloudNativeCon Europe 2026から、カンファレンス初日のキーノートセッションを紹介する。プレゼンテーションを行ったのは、The Linux FoundationのCloud&InfrastructureのExecutive Director、Jonathan Bryce氏と同じくCloud&InfrastructureのCTOであるChris Aniszczyk氏だ。
この部分の動画は以下から参照できる。
●参考:Keynote: Welcome + Opening Remarks

巨大なステージに立つBryce氏とAniszczyk氏
前半はKubeCon自体が拡大していることを確認する内容で、過去最大の13,500人が参加していることを語った。

過去最大の規模となったアムステルダムのKubeCon Europe 2026
rコミュニティについては230を超えるプロジェクトが存在し、コントリビューターも30万人を超えるエンジニアが191の国と地域から参加していることを説明した。デベロッパーについては6か月前には1560万人だったものが、1990万人に拡大していると説明。
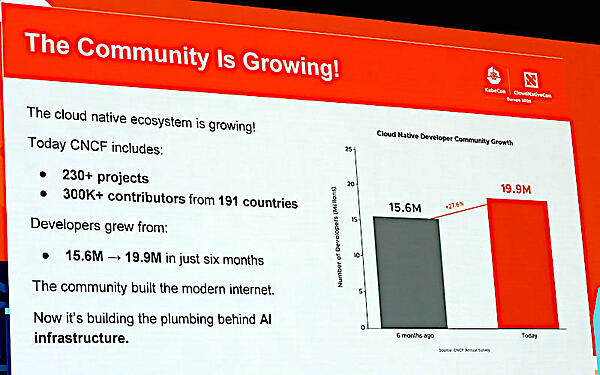
コミュニティの成長を紹介
国と地域別ではヨーロッパが38.39%、アメリカが35.37%で、以下はインド、中国、カナダという順番だ。ヨーロッパを国別ではなくひとくくりにした辺りにヨーロッパを総体として賞賛したいというCNCF/LFの意図が透けて見えていると言える。

国と地域別のコントリビューションの概要
CNCFがホストするプロジェクトもサンドボックス、インキュベーション、グラジュエーションのそれぞれのレベルで拡大しているとして、Agones、HAMi、llm-dがサンドボックス、Fluid、Tektonがインキュベーション、DragonflyとKyvernoがグラジュエーションプロジェクトとして紹介された。

CNCFがホストするプロジェクトの拡大を紹介
またCNCFが持続的に活動する資源でもあるメンバーシップについても紹介。ここではゴールドとしてF5とVittel、そしてその他のレベルの新規メンバーを紹介。UberやClickHouseも新規加入の企業である。細かいところでは日本国内でLinuxの技術認定試験(LinuC)を運営するLPI-Japanが非営利団体メンバーとして加わった。これは2026年7月29日、30日に横浜で開催されるKubeCon Japan 2026に向けた準備と言ったところだろうか。

新規メンバーの加入も増えていることを強調
CNCFに加入しているエンドユーザーにとってはユースケースをリファレンスとして使えることが大きな価値だが、国をまたいで地下に構築されている大型ハドロン衝突型加速器を持つCERNやスイスのテレコムオペレーター、Swisscom、メガネやレンズの製造元Zeissなどのヨーロッパのエンドユーザーのリファレンスアーキテクチャーを取り上げているページも紹介された。まだ10件にも満たないユースケースだが、これまでキーノートなどで何度も紹介されたシステムを一覧できるという意味では役に立つだろう。利用されているCNCFのプロジェクトも紹介されている。CNCFのランドスケープがプロジェクトのカテゴリーに一覧できる機能だとすれば、これはユーザーを軸に何が使われているのか? を知るための工夫となる。公式ページは以下の通りだ。
●CNCFリファレンスアーキテクチャーページ:https://architecture.cncf.io/
そして何よりも大きな新規メンバーに関するニュースはNVIDIAだろう。

NVIDIAがCNCFのプラチナメンバーとして加入
ここでNVIDIAのスタッフが登壇し、過去10年でクラウドネイティブなシステムはLinuxとKubernetesによって大きく変わってきたことを説明。しかしこれはNVIDIA的にはNVIDIAのGPUが現在の生成AIの隆盛を支えてきたことが最も言いたいことであったろう。そしてNVIDIAはオープンソースを支援し続けていることを強調。2017年から現在まで多くのドライバーやツールを公開していると年表スタイルで説明を行った。

NVIDIAが公開したオープンソースツールなどを振り返る
NVIDIAのGPU向けのDRAドライバーをKubernetesのリポジトリーにマージしたプルリクエストなども参照しながら、いかにNVIDIAがオープンソースコミュニティに貢献しているのかを解説した。
ここからはAIのワークロード、特に推論が重要であることを強調する内容にシフトした。説明を行ったのは冒頭の2人組、Jonathan Bryce氏とChris Aniszczyk氏だ。
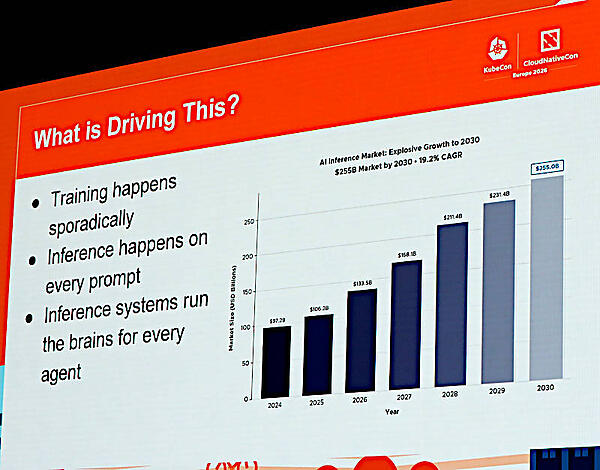
アトランタでも語られた学習よりも推論が重要というテーマ
ここではモデルの学習は最新の情報を学習したフロンティアモデルの新バージョンの発表などのように不定期に行われるが、推論はプロンプトが入力されるたびに実行されているからというシンプルな事実だ。
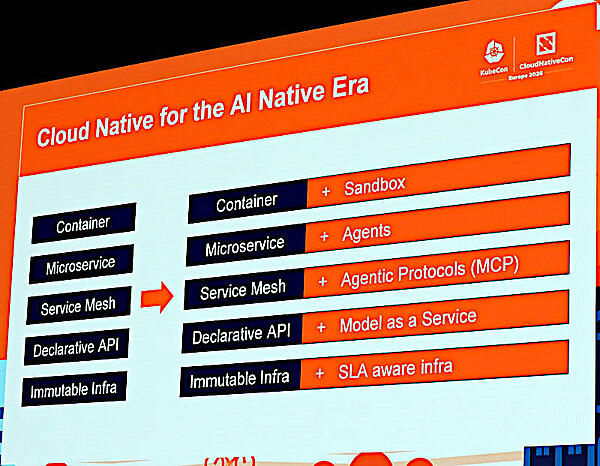
クラウドネイティブなシステムの特徴をAIに重ね合わせて解説
ここでクラウドネイティブなシステムの分散システム、オーケストレーション、ネットワーク、オブザーバビリティ、スケジューリングなどの特性が生成AIの時代にどう変化していくのか? を解説。コンテナはサンドボックス機能を備える必要があり、マイクロサービスにはエージェントが追加され、サービスメッシュにはMCPがプロトコルとして使われ、宣言的なAPIには大規模言語モデルがサービスとして使われる。アタックされるリスクを劇的に軽減するイミュータブルなインフラストラクチャーにはサービスレベルの保証が必須となると説明。このスライドはクラウドネイティブなシステムの用語には詳しくてもそれが生成AIの時代にどう変化するのか、位置付けられるのかを知りたいといういわばクラウドネイティブなシステムの保守派のための見取り図と言ったところだろう。

推論実行のためのフレームワーク、llm-dを紹介
rここからllm-dを紹介する段階となった。llm-dがCNCFのサンドボックスプロジェクトになったことを語った後にプロジェクトのメンバーを登壇させて解説を行った。推論がシングルサーバーから分散に発展していくなかで、llm-dは大規模言語モデルに特化したロードバランシングやKVキャッシュの管理、PrefillとDecodeジョブの分散と集約、複数のノードをまたいだ並列処理のスケジューリングなどを実装してきたと説明した。llm-dはRed Hat、IBM、Googleなどが貢献する新しいプロジェクトだ。
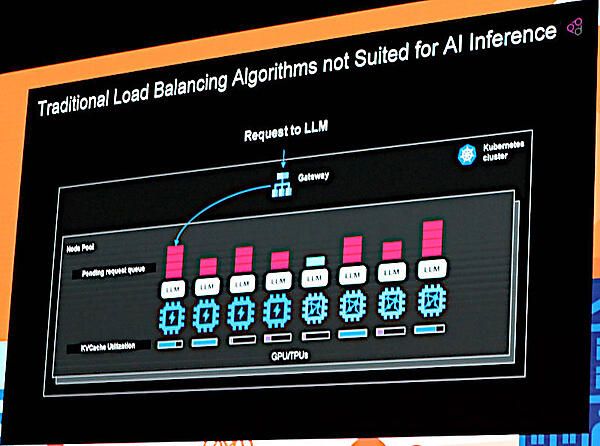
従来のロードバランサーはAIの推論には適していないと説明した
大規模言語モデルの特徴的なPrefill/Decodeの処理を分離して集約するサービスが求められていることを説明するスライドでは、PrefillとDecodeで生成されたトークンを、KVキャッシュを通してメモリー間転送を行うことで高速化する仕組みを解説。
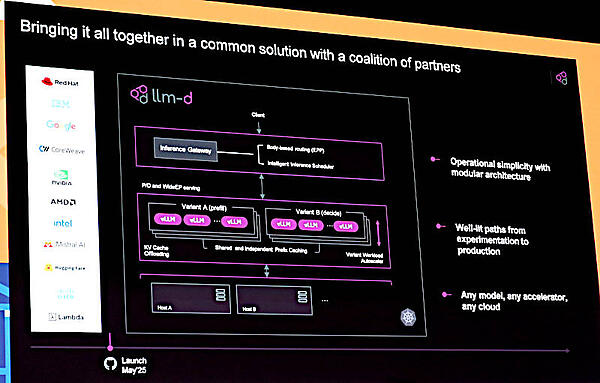
llm-dのアーキテクチャーと貢献している企業を記したスライド
このスライドではllm-dの全体のアーキテクチャーに加えて貢献している企業名がアイコンで記されており、Red Hat、IBM、Googleがプロジェクトをリードしていることがわかる。
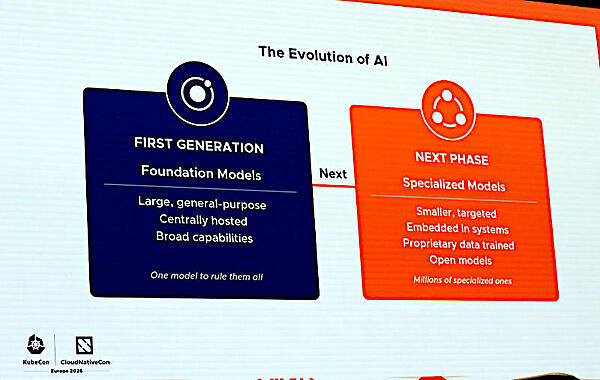
生成AIのモデルは汎用から専用のモデルに移行しつつあると説明
GoogleやOpenAI、Anthropicなどがしのぎを削る大規模言語モデルについては、汎用の知識を持つフロンティアモデルからドメインに特化した知識を学習したモデルを利用する方向に向かっていると説明。専用モデルはより小さく高速、システムに組み込みやすいという特性を持っていると説明した。

専用モデルが重要になってきている背景としてコスト、性能、GPU枯渇などが挙げられている
ここでエンドユーザーとしてUberのMelda Selhab氏が登壇し、Uberが開発したMichelangeloというAIを解説する段階となった。

Uberが開発したAI、Michelangelo AIを解説するレバノン出身のデータサイエンティスト、Selhab氏
UberのAIはMichelangelo AIという名称で社内の各種サービスで利用されているという。
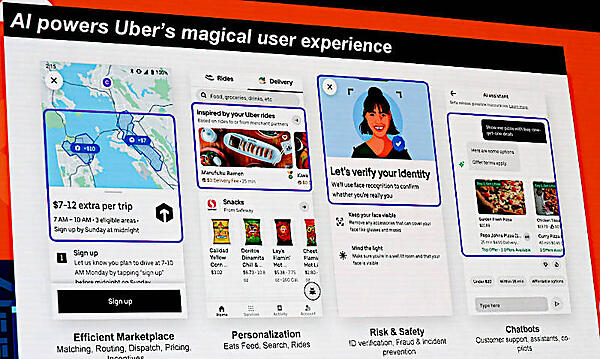
Uberのさまざまなシステムで利用されているMichelangelo
ドライバーとユーザーのマッチングだけではなくルート選択やパーソナライゼーション、セキュリティなどの部分でも使われているという。

機械学習から始まったUberのAIはスケールすることが大きな課題
説明の中でトラディショナルな機械学習から始まったUberのAIは当初からスケールすることが最重要な要件であったと説明した。ライドシェアから始まり、さまざまなアプリケーションに展開しているUberのサービスは日本のインターネットサービス、スマートフォンアプリデベロッパーには関心が高い内容だろう。
最後のパートはCNCFがリードするAIに関するコンフォーマンスプログラムに関する内容だ。このためにステージに登壇したのはGoogleのエンジニア、Janet Kuo氏だ。
GKEを使ってコンフォーマンスを確認するKuo氏
Kuo氏はGKEをターミナルから使いながら、実際にコンフォーマンスプログラムに準拠しているかを確認するデモを見せながら解説。AIのワークロードがKubernetes上で実装される時に移植性や互換性が保たれているかどうかを確認するのが目的で、3大クラウドプロバイダーだけではなくRed HatやSpectro Cloud、China Unicomなども参加しているプログラムになる。2025年11月にアトランタで開催されたKubeCon North America 2025で発表された詳細な内容については、以下の公式リンクを参照して欲しい。
●参考:CNCF Launches Certified Kubernetes AI Conformance Program to Standardize AI Workloads on Kubernetes
最後にまたJonathan Bryce氏とChris Aniszczyk氏がステージに戻り、オープンな開発スタイルとそれを支える透明性の高いコミュニティが重要だと強調してキーノートの最初のパートを終えた。

オープンであることが生成AIでも重要と訴えた
全体としてオープンソースコミュニティの着実な拡大と生成AIにおいてはモデル学習ではなく推論こそがビジネスにとって重要であることをNVIDIAやUberの知名度を使って何度も強調した内容となった。AIがビジネスを変革している現時点で明るい面に焦点を当ててオープンであることの必要性を訴求していたが、コントリビューターにとっての明るくない面、つまり生成AIがコードを書くことでプルリクエストが激増し、これまで以上にプロジェクトのメインテナーやレビュワーが疲弊していくというオープンソースプロジェクトとして避けられない問題は敢えて語らなかったことは、コミュニティが重要だと言い続けているCNCFとしてはやや物足らない印象であったと言える。