
OpenAI が発表した2025年10月最新の脅威レポートで、AI を新規のサイバー攻撃や詐欺の手口の核ではなく既存のワークフローに組み込む動きや複数モデルの併用している事、可観測な“AIらしさを消す隠蔽の活動などがポイントとして記載されていました。
なお、OpenAI は利用規約に違反した40を超えるネットワークを発見・停止しています。
関連:AIや生成AIの悪用事例や事件を解説
組織犯罪型の詐欺ネットワーク:AIは“拡張器具”、防御側でも“増幅器”
ここ半年だけでも、カンボジア・ミャンマー・ナイジェリア起源と推定されるスケール型の詐欺運用を複数停止したといいます。
典型的フローは「Ping(接触)—Zing(煽動)—Sting(詐取)」の三段で
SNS 広告や魅力的な求人や金融サービスのメッセージをばらまき、コンタクトを取った後、対象者の熱狂や不安を煽って送金や秘匿情報を抜き取ります。
ここでAIは、翻訳や文面生成、広告素材作成、基礎調査などの補助業務に悪用されています。
悪用より防御のAI活用が3倍多い
注目すべきなのは、防御側でのAI の増幅効果です。
OpenAI は、ChatGPT が詐欺の見抜きに月間何百万回も使われている兆候を観測し、
「悪用より最大3倍多く、詐欺検知に使われている」と推計。
実地の調査でも、以下では同社の研究員が詐欺SMSメッセージのスクリーンショットをChatGPTに貼り付け、モデルを用いて詐欺であると特定することに成功した例です。
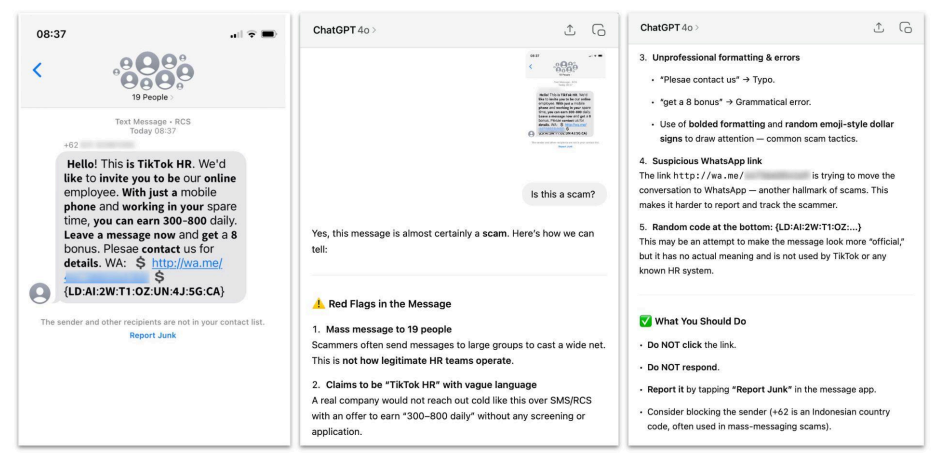
この事例では、脅威アクターはTikTokのリクルーターになりすまそうとしていました。
彼らは検出回避のため、コンテンツからエムダッシュを削除する指示や、プラットフォームBANを競合の虚偽申告のせいにする“言い訳”文面の生成も確認。
中国語圏クラスター:「フィッシング&スクリプト」と
報告は、中国語圏のアカウント群が中国語(簡体・繁体)/英語/日本語でのフィッシング文面の作成、ツールやマルウェアの開発補助にChatGPTを利用。
AESによるC2暗号化の議論など一定の技術理解を示す一方、静的鍵など未熟さも見られました。
さらには他AIモデル(DeepSeek 等)での自動化余地を調査するなど、モデル間をまたぐ活用が進んでいる実態も指摘します。
ロシア語圏でのAIを活用したマルウェア開発支援の試み
ロシア語圏の犯罪グループに連なるとみられるアカウント群が、RAT(遠隔操作トロイ)や資格情報窃取、検知回避機能などのマルウェアの部品開発をAIに手伝わせようとした事例です。
AIのモデルは露骨な要求を拒否し続けたため、
攻撃者は「EXE からのシェルコード化」「メモリ内ローダ」「ブラウザ資格情報解析」等の“ビルディングブロック”の生成や、クリプタ/難読化のコード片、クリップボード監視、Telegram ボット経由の簡易持ち出しスクリプトといった周辺ユーティリティの試作にとどまりました。
技術的には、Win32 API や DPAPI、AES-GCM での Cookie 取り扱い、Chrome DevTools 自動化といった低レイヤの相談から、パスワード大量生成や“自動応募”のような雑務の自動化まで混在。
少数のアカウントを用い、同じコードを会話を跨いで反復的に磨く振る舞いが継続開発のパターンを示していました。
韓国語圏オペレーター:スピードとローカライズを最重視
別事例では、韓国語圏のオペレーターが暗号化 C2 と遠隔コマンド実行の部材(AES-GCM、セッション再鍵、System ビーコン、WebSocket/HTTPS 経由の PowerShell 実行)や、トラフィック防護と OPSEC の微調整(WSS/TLS への移行、CDN/TLS フロント、証明書検証回避のテスト)、偵察とプロセス制御(AV 検出、プロセス列挙、Edge/WebView2 の特定プロセス終了)、コモディティ・スキャナ(nuclei、fscan)の利用手順、多言語の説得的メール生成などを相談。ねらいは新能力の獲得ではなく、反復の短縮とローカライズの精度向上にありました。
再犯型 IO:「Stop News」は画像偏重から“テキスト・動画脚本”へ
2024年秋に露出したロシア発の偽ニュース網「Stop News」は、OpenAI と各社の妨害後も戦術の再編を試み、今回の観測では画像生成の比率を大きく下げてテキストが中心になっています。
さらに、ロシア語長文→仏語への翻訳→SEO 最適化説明文とハッシュタグという短尺動画の台本づくりにもモデルを使っていました。
とはいえ全体の浸透度は低く、関与アカウントの多数がほぼ無反応のまま散在。
英・仏の機関や研究者が示した通り、過去に見られた“外部サイトとの提携”も実は技術的欠陥の悪用による虚偽だった可能性が高いと評価を修正しています。
全体を通して
レポート全体を通じて見えるのは、AI は攻撃者の手間を圧縮し、言語とローカライズの壁を低くする一方で、未知の攻撃術や革命的突破をもたらしてはいないという点です。
攻撃者は短い反復で試作を重ね、うまくいかないときのすぐ直す工程や、多言語展開の摩擦を和らげるためにモデルを使い、AIらしさの痕跡(em ダッシュ等)を隠す方向へと適応しています。
防御の側では、同じモデルが詐欺の見抜きや早期警戒**の“増幅器”として働いている——検知と隠蔽の綱引きが、複数モデルを横断して続いているのです。
出典
Disrupting malicious uses of AI: an update
この記事をシェアする
メールマガジン
最新のセキュリティ情報やセキュリティ対策に関する情報をお届けします。
投稿者:三村
![]()
セキュリティ対策Labのダークウェブの調査からセキュリティニュース、セキュリティ対策の執筆まで対応しています。
セキュリティ製品を販売する上場企業でSOC(セキュリティオペレーションセンター)やWebサイトやアプリの脆弱性診断 営業8年、その後一念発起しシステムエンジニアに転職。MDMや人事系のSaaS開発を行う。