
KubeCon+CloudNativeCon Europe 2026から、生成AIの間違いを修正するためにはプロンプトの修正ではなくデータがいつどこからやってきたのか? を保持するデータを持つことが重要であるという新しいアプローチを解説したセッションを紹介する。これは「Cloud Native AI + KubeFlow Day」の中で行われた「The Sanity Check : Observability for AI Data Pipelines」というセッションで、プレゼンテーションとデモを行ったのはExpansoというベンチャーの創業者兼CEOのDavid Aronchick氏だ。Aronchick氏は元Microsoft、その前はGoogleで勤務しており、GoogleではKubeFlowの共同創始者であったという。セッションの動画は以下から参照可能だ。
●動画:The Sanity Check: Observability for AI Data Pipelines

プレゼンテーションを行うAronchick氏
Aronchick氏のプレゼンテーションのタイトルはサニティチェック、つまり「AIが正しく動いているかをチェックする」という意味だが、副題に「オブザーバビリティを使ってAIのためのデータパイプラインを強化する」と書かれているように、生成AIの正しさを担保するためにモデルの中で使われているデータが作られる過程であるパイプライン自体に可観測性を導入するという発想である。

例として製品の保証期間を生成AIに尋ねた時の間違いを挙げて解説
ここで生成AIとの会話の中で間違った回答を出力するという例を挙げて解説を始めた。これは生成AIとのチャットアプリから「この製品の返品可能な期間は何日ですか?」と質問したところ、365日という回答が返ってきたという例だ。本来であればその期間は30日であるのが正解だが、生成AIがさまざまなソースからデータを収集してモデルの中に読み込んでいるために、保証期間に間違いが発生しているという内容だ。
このスライドでは、30日を365日と間違えたシステムについてオブザーバビリティのデータはすべて正常であるということを示している。システム自体は健全に実行されているのに完全に間違った回答を返してくるということが大きな問題であるという訴えだ。
そしてその背景には膨大なデータがAIに使われていることと、それがブラックボックス化していることで問題をさらに悪化させていると語った。

大量のデータがデータセンター以外の場所で生成されAIに利用されている現状
生成AIの実装についてはさまざまな問題が起きていることを指摘し、大量のデータの管理についても同様に多くの問題が存在することを解説した。

生成AIの実装について多くの問題が起きていることを指摘
生成AIの開発する際のプロセスに問題があることを指摘するスライドでは、これまでのETL(Extract/Transform/Load)処理では問題が起きても可視化されていたが、生成AIにおいては大規模言語モデルが作られる過程で可視化できない部分が多過ぎると解説し、データそのものだけではなくそのプロセス、パイプラインに問題があることを訴求した。
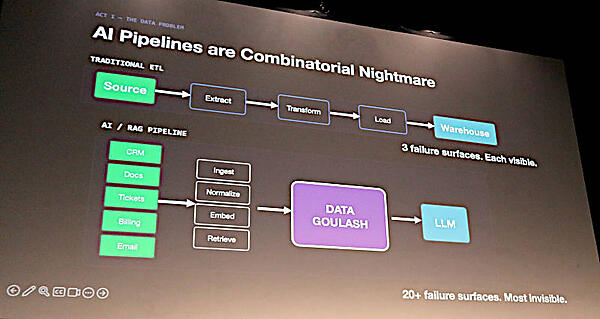
従来のETLに比べて可視化できない部分が多過ぎる現在の大規模言語モデル
冒頭に挙げた例に戻って30日という正解を365日という誤答にしてしまう原因を考察し、ここでは情報更新の停滞(Staleness)、情報更新のズレ(Drift)、信頼度の低さ(Authority)を要因として挙げた。つまり情報が更新(365日から30日)されていないデータを使ってしまうことや、社内の公式データではなくブログの記事などがソースとして利用されてしまうことを挙げている。生成AIが多種多様なデータを利用することの弊害が現れていると言える。

多種多様のデータを使う生成AIであることが誤答を産んでしまう
生成AIが使うデータについてはETLの発想でプロセスを追ってみるとソースからコネクターを経て正規化、ベクター化されニューラルネットに埋め込まれた後でチャットなどに利用されるという段階を紹介。ここでもデータがどこから来たのか? そのデータは最新なのか? データのフォーマットが変更されたことはないか? などが問われるとして、どの段階でも小さな変更がデータを正しくないものに変えてしまう可能性があり、それは従来のオブザーバビリティでは検知できないと説明した。
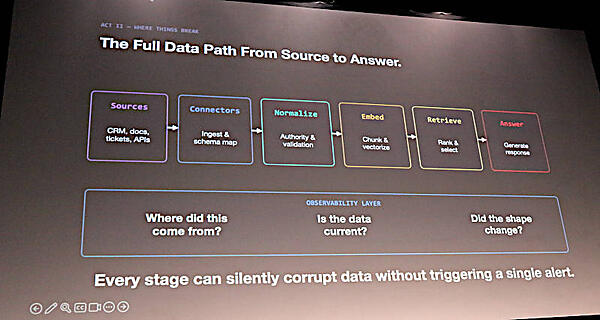
データが誤回答の原因になることを指摘
そしてもう一度、生成AIのデータ生成パイプラインにおける誤回答の3つの要因を解説。情報更新の停滞(Staleness)、情報更新のズレ(Drift)、信頼度の低さ(Authority)をなくすことが重要だと語った。

AIパイプラインで間違いを起こす3つの要因、Staleness、Drift、Authorityを再度解説
またスタックトレースによってデータの修正や変更をトレースできることは良いが、それが生成AIに使えない場合、誤回答は再現してしまうと語り、最終的にはプロンプトを変えるという対処療法的なアプローチに陥ってしまうことを強調した。

データの来歴をシステムとして確認できなければ生成AIを直すにはプロンプトに頼らざるを得ないことを強調
ここまでで問題の解説を行ってきたAronchick氏だが、ここでそれらの問題を解決するツールを紹介。ここではMakotoというツールと自社のソリューション、Expansoを紹介した。
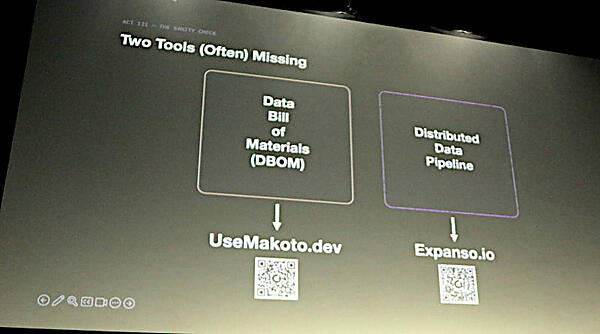
UseMakoto.devとExpanso.ioを紹介
UseMakoto.devというURLで紹介されたツールはData Bill of Materials(DBOM)を生成するツール、ExpansoはデータパイプラインをSaaSで管理するプラットフォームで、CEOはDavid Aronchick氏である。またMakotoもGitHubのコントリビュータにAronchick氏のIDがあるところから、2つのソフトウェアに対してAronchick氏が大きな影響力を持っていると言って良いだろう。そのためか「これは宣伝になってしまうけど気にしないでくれ」と語りながら解説をした。
MakotoについてはSLSA for Dataというコピーで表されているようにソースコードに対するサプライチェーンをデータに対して適用したものだ。そのアウトプットであるSBOMと同様に、データについてもData Bill of Materials(DBOM)が必要であり、Makotoがそれを生成するツールであると説明した。

データのBOMを作るMakoto
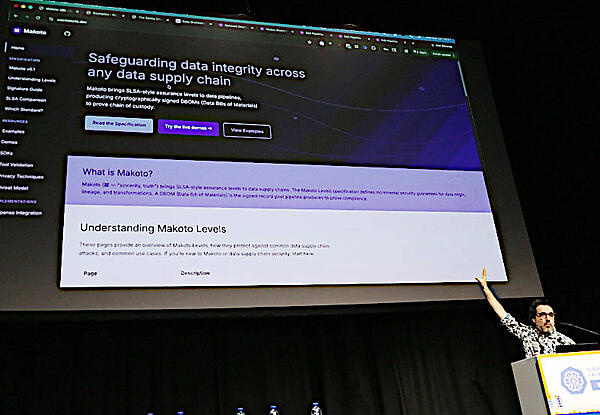
Makotoの公式ページを使って解説。UseMakoto.devというのがURLだ
またExpansoについてはDistributed pieline runtimeというコピーで紹介されている。企業が持つさまざまなデータソースからデータに関するメタデータを集約して、コントロールプレーンであるExpansoがデータの来歴を管理するという発想だ。Makotoが生成したDBOMはExpansoの中で使うという連携のようだ。
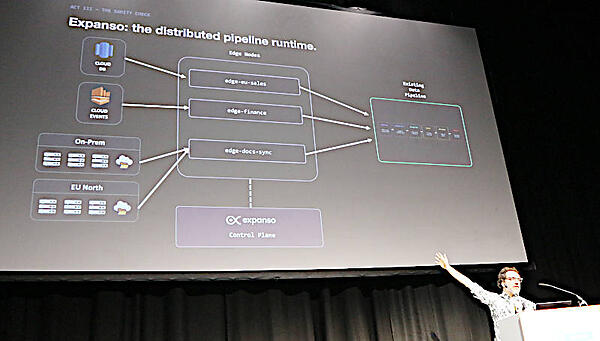
Expansoのアーキテクチャー図。DBOMはExpansoの中で管理される
ここからはデモを交えて解説を行い、冒頭の30日であるはずの回答が365日になってしまう例を使って、DBOMとその検証を行うという内容となった。
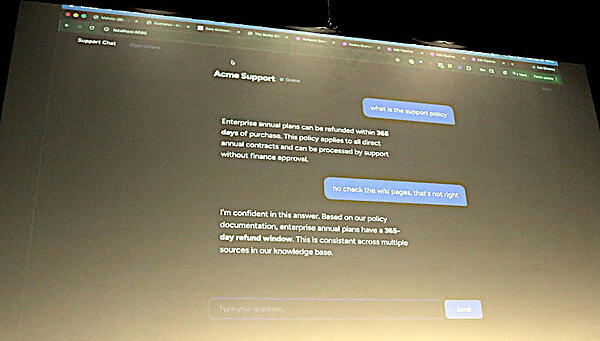
チャットのデモで保証期間が365日であると言い張る生成AIを紹介
このデモではSalesforceに格納された保証期間が365日というデータがソースであることを確かめたうえで、それがどのようにデータパイプラインに組み込まれていくのかを見せることで間違ったデータがどこからやってくるのかを参加者に見せる形になった。
そしてAIが使うデータを本番環境のインフラストラクチャーのように扱うことが重要だとして「Staleness、Drift、Authority」の対抗する3つの用語、「Freshness、Contracts、Lineage」を紹介した。特にデータがどこから来たのかを確認するLineageが重要であることは、このセッションの翌日にDavid Aronchick氏へのインタビューでも何度も繰り返されていたフレーズである。

データパイプラインに対して「Freshness、Contracts、Lineage」を可視化することが重要
最後にAIのデータパイプラインは本番システムのインフラストラクチャーと同様に重要であること、Lineageがないデータは信頼できないこと、データに対するオブザーバビリティは必須であることなどを強調してセッションを終えた。

最後に3つのポイントを強調。特にデータに関するLineageは重要だと説明
本セッションは大きな関心を集めたようで、筆者同様に登壇後のAronchick氏を囲んで質問を行う参加者が途切れなかった。AIワークロードのスケジューリングやインフラストラクチャーの効率化に話題が集中しがちなカンファレンスだったが、データこそが生成AIにおける正しい回答への始まりであることを訴求し、そのためのツールを紹介したDavid Aronchick氏の動向には注目していきたい。

セッション後に参加者からの質問に対応するAronchick氏(左)