
Gemini APIなどを通じて自動化エージェントを構築
![]()
1
会員(無料)になると、いいね!でマイページに保存できます。
共有する
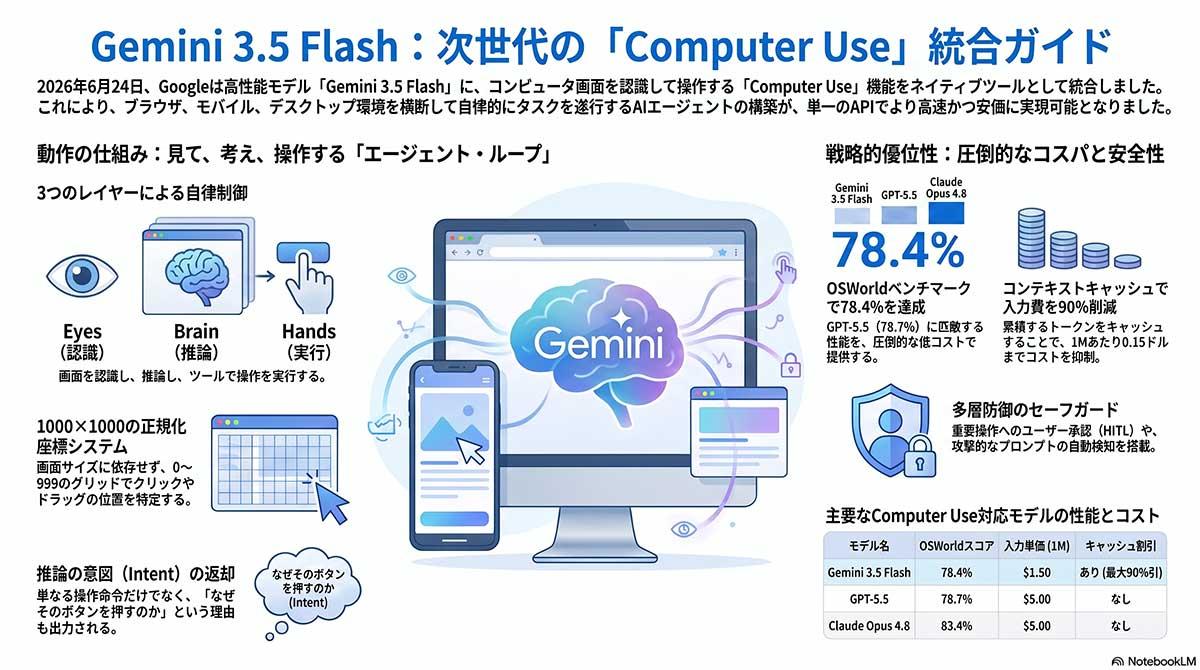
Googleは2026年6月24日、AIモデル「Gemini 3.5 Flash」に、画面を認識して自律的に操作を実行する機能「Computer Use」を統合したと発表した。これまで独立したプレビュー版として提供していた機能を主力軽量モデルに組み込み、開発者はGemini APIなどを通じてブラウザやデスクトップ環境における自動化エージェントを構築できるようになった。

(画像:ビジネス+IT)
AIエージェントが人間の物理的な入力プロセスを模倣し、画面情報を視覚的に認識しながらOSやアプリケーションを操作する「Computer Use」技術が、Geminiの標準機能として実装された。Google DeepMindの開発した「Gemini 3.5 Flash」は高効率な軽量モデルであり、本機能の統合により、AIが自ら画面の要素を解釈し、マウスクリックやキーボード入力といったアクションを生成して実行環境に引き渡す処理をシームレスに行う。
従来、同機能は「Gemini 2.5 Computer Use preview」という専用のスタンドアロンモデルで検証が進められていた。別個のAPI上で動作する実験的システムであったため、開発者は複数のモデルを組み合わせる必要があり、システム構造の複雑化や遅延の増大を招いていた。今回のアップデートで、Gemini 3.5 Flashの標準APIにおける組み込みツールとして宣言可能になったことで、単一モデルによるマルチツールコンポジションが実現する。
【図版付き記事はこちら】Google、Gemini 3.5 FlashにPC画面操作のComputer Use標準搭載(画像:ビジネス+IT)
性能面では、コンピュータ操作のベンチマークである「OSWorld」において、Gemini 3.5 Flashは78.4のスコアを記録した。旧バージョンのGemini 3 Flashの65.1から向上しており、複雑なマルチステップの課題解決に対応する。
企業の業務プロセス自動化に向けた安全対策も導入した。プロンプトインジェクション攻撃を防ぐための敵対的学習を適用しているほか、機密性の高い操作や不可逆的なアクションを実行する前にユーザーの確認を要求するエンタープライズ向けの保護機能を提供する。
開発者や企業は、Gemini APIやGoogle Cloudの「Gemini Enterprise Agent Platform」を通じて同機能を利用し、ソフトウェアテストや定型業務の自動化など、多様な環境で機能するエージェントを構築する基盤を整えた。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
![]()
評価する
いいね!でぜひ著者を応援してください
会員(無料)になると、いいね!でマイページに保存できます。
関連タグ
タグをフォローすると最新情報が表示されます